Wie gut ist dein Machine-Learning-Modell?
Oder: Wie ich Null Punkte im Google Test bekam
Oliver Zeigermann / @DJCordhose
Eine kleine Umfrage
- Wer versioniert seine Modell-Spezifikation?
- Wer macht Code-Reviews Modell-Spezifikation?
- Wer vergleicht mit einem (nicht-trivialen) Baseline-Modell?
- Wer hat Unit-Tests für den Trainingscode?
- Wer hat eine Deploy-Pipeline?
Mein Eindruck
Verglichen mit Software-Entwicklung sind wir mehrere Jahre zurück
Wir illustrieren die Anforderungen anhand einer Beispielbewertung
Wir sind uns aber bewusst: Google löst andere Probleme als die meisten von uns
Unser Projekt
Customer Churn / Conversion
Wie verhält sich jemand, der später Kunde wird / kündigt?
Technik / Umsetzung
- Präprocessing mit Pandas/Sklearn
- Modell mit TensorFlow/Keras
- Deployment auf Google Cloud ML
Bewertung
Ein Punkt für das Erfüllen eines Test-Kriteriums
Ein weiterer falls die Erfüllung automatisiert ist
Vier Kategorien mit jeweils maximal 14 Punkten
Kategorie 1
Features und Daten
Test: Verteilung der tatsächlichen Features entspricht den Erwartungen
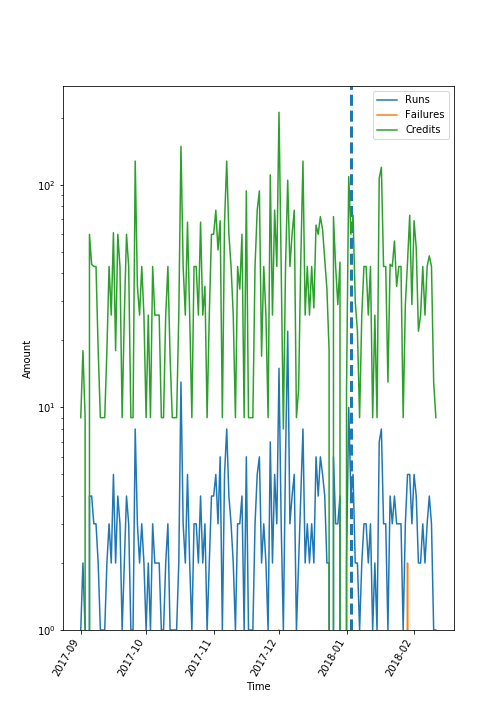
Unser Projekt: Manueller Plot
1 Punkt!
Test: Beziehung zwischen den Features
Unser Projekt: Korrelation Plot
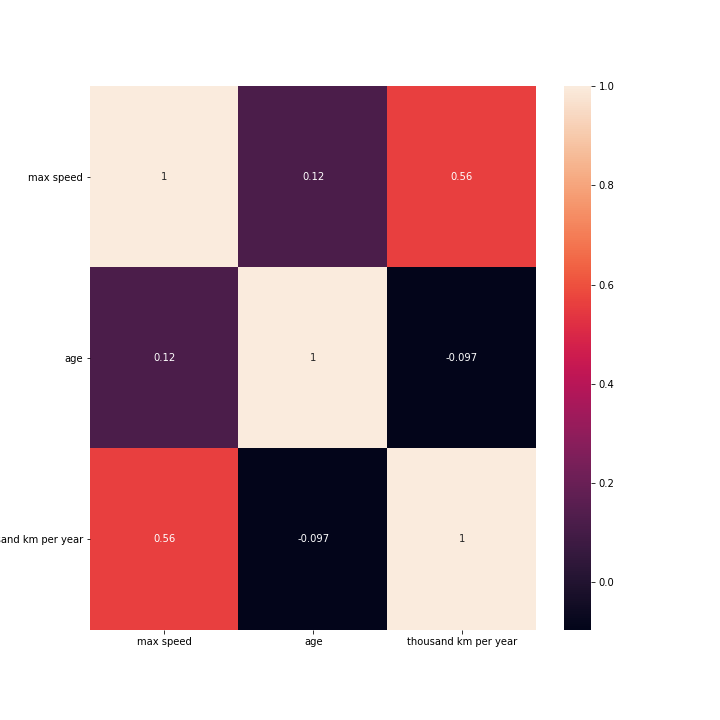
Noch ein Punkt! Es sind jetzt schon zwei!
Test: Wie teuer ist ein Feature?
Wie teuer ist die Beschaffung? Wie viele Ressourcen belegt es im Modell?
Test: Sind die Feaures brauchbar?
Ist das Feature immer verfügbar und von konstanter Qualität?
Test: Werden Privacy Belange in der kompletten Kette eingehalten?
https://www.heise.de/newsticker/meldung/DSGVO-Folterfragebogen-im-Selbsttest-3974512.html
Unser Projekt: Daten werden von vorn herein nur anonymisiert verwendet
str(hashlib.sha512(license)).hexdigest())[:8] + '@example.com'
Zwei Punkte, da das hier automatisiert ist! Vier insgesamt!
Test: Wie lange dauert es, ein Feature hinzuzufügen?
Wie schnell kann reagiert werden?
Test: Funktioniert der Code, der Features für Test und Produktion liefert?
Auch so simpler, aber extrem wichtiger, zentraler Code braucht Unit-Tests
Ergebnis
Features und Daten
4 von 14 Punkten
3-4 points: There’s been first pass at basic productionization, but additional investment may be needed.
Kategorie 2
Modell-Entwicklung
Test: Ist die Modell-Spezifikation versioniert und unterliegt einem Code-Review?
Unser Projekt
- Modelle werden in Jupyter Noteboks entwickelt
- Modell-Spezifikationen selbst wird in puren Python-Code gewandelt und in Git versioniert
- Entweder Pair-Programming oder Code Review
Zwei Punkte
Test: In welchem Zusammenhang stehen Modell Metriken und Auswirkung in der echten Welt?
Wenn sich der Test-Score erhöht, kann man dann eine Auswirkung auf relevante Business-Größen ferstellen? Kaufen mehr Leute? Sind Kunden zufriedener?
Unser Projekt
Wie für jedes Feature wollen wir das überprüfen, dies ist bisher aber nicht geschehen
Kein Punkt
Test: Welchen Einfluss haben Hyper-Parameter auf das Ergebnis?
Systematische Untersuchung von Hyper-Parametern kann zu deutlich besseren Ergebnissen führen
Unser Projekt
Parameter-Raum ist zu groß und Laufzeit für Training zu lang für Grid-Search, wir nehmen Random-Search
Zwei Punkte
Test: Passt sich das Modell an die Entwicklung der Daten aus der realen Welt an?
Verhält sich das Modell mit Daten von dieser Woche anders als das von letztem Jahr?
Unser Projekt
Besteht noch nicht lang genug, um das sicher sagen zu können
Kein Punkt
Test: Liefert das Modell bessere Ergebnisse als ein Baseline-Model?
Wenn ja, mit welchem Aufwand erreichen wir das bessere Ergebnis? Lohnt sich das eigentlich?
Unser Projekt
Unser Baseline-Modell ist ein von Hand kodiertes stochastisches Modell
Unser ML Modell ist auf Testdaten 20% besser und passt sich an die Daten an
Ein Punkt!
Test: Wie verhält sich das Modell wenn man es nur auf Teildaten anwendet?
Betrachtung z.B. nach Land kann Schwächen zeigen, die im Gesamtmodell untergehen
Test: Gibt es impliziten Bias?
Decken die Trainingsdaten alle realistischen Szenarien ab
Unser Projekt
Wir wissen sicher, dass wir Bias in den Trainingsdaten haben
Dazu gibt es von bestimmten Daten viel und von anderen weniger Datensätze
Kein Punkt!
Ergebnis
Features und Daten
5 von 14 Punkten
5-6 points: Reasonably tested, but it’s possible that more of those tests and procedures may be automated.
Kategorie 3
Machine Learning Infrastruktur
Test: Sind die Trainingsergebnisse reproduzierbar?
Liefern Modelle, die auf denselben Trainingsdaten trainiert werden dieselben Ergebnisse?
Unser Projekt
Ist gewährleistet
Ramdom Seeds fest gesetzt
Initiale Weights immer gleich geladen
Zwei Punkte
Test: Gibt es Unit-Tests für den Trainingscode?
Geht Loss beim Training tatsächlich herunter? Kann man nach einem Crash wieder aufsetzen? Funktioniert Early-Stopping? Sind Checkpoints brauchbar?
Unser Projekt
Loss wird über das TensorBoard überprüft (manuell)
Early Stopping Callbacks wenn Validation Loss nicht mehr herunter geht
Checkpoints werden geschrieben
Ein Punkt, keine automatische Überprüfung
Test: Gibt es Integrationstests für die komplette Pipeline?
Test: Wird die Modell-Qualität vor Produktivstellung getestet?
Funktioniert das Modell besser als ein vorheriges? Werden bekannte Ergebnisse richtig vorhergesagt?
Unser Projekt
Accuracy aller Test-Daten wird automatisch berechnet
Ausgewählte Datensätze werden nur manuell überprüft
Ein Punkt (bekannte Ergebnisse könnten Unit-Tests sein)!
Test: Verhält sich das Modell nachvollziehbar?
Kann man das Verhalten nachvollziehen wenn man es nur mit einem Datensatz füttert?
Was passiert wenn man einen kleinen Trainingsdatensatz füttert?
Hat man irgendeinen Einblick in die internen Abläufe des Modells?
Unser Projekt
Bei Convolutional Layers nutzen wir die bekannten Strategien
Manuell überprüfen wir Aktivierungen von Feature Channels, Activation Maps, und welche Feature Channels pro Bild angesprochen werden
Fully Connected Layers sind allerdings komplett intransparent
Ein Punkt!
Test: Gibt es im Staging-Prozess ein System, das Production nachempfunden ist?
Nur so kann man sicher stellen, dass System-Änderungen aus dem Training auch in Produktion Funktionieren
Unser Projekt
Auf Google Cloud ML ist ein Modell mit einer bestimmten Version default
Diese Versionsnummer kann jederzeit umgesetzet werden
Ein Punkt!
Test: Kann ein Modell sicher und schnell aus Production zurück gerollt werden?
Unser Projekt
Manuell, aber auch dafür ist Google Clound ML gut geeignet
Produzierte Modelle werden aber auch im Git mitversioniert
Ein Punkt!
Ergebnis
7 von 14 Punkten
7-10 points: Strong levels of automated testing and monitoring, appropriate for missioncritical systems.
Kategorie 4
Monitoring
Test: Kommen Daten von weiteren Systemen weiterhin in richtiger Menge an?
Das kann sich auf regelmäßiges (Nach-)Training beziehen und sich auf die Trainingszeiten auswirken
Ergebnis
0 von 14 Punkten
0 points: More of a research project than a productionized system.
Hier muss noch viel passieren
Endergebnis
Das Minimum eines Ergebnisses jeder Kategorie
Das bedeutet leider insgesamt 0 Punkte
0 points: More of a research project than a productionized system.
Der Vollständigkeit halber: Die restlichen Bewertungen, die wir nicht erreicht haben
- 5-6 points: Reasonably tested, but it’s possible that more of those tests and procedures may be automated.
- 12+ points: Exceptional levels of automated testing and monitoring.
Zusammenfassung
- Machine Learning läuft klassischer Software-Technik um Jahre hinterher
- Wenige haben dieselben hohen Anforderungen an ihr Modell wie Google
- Bewusstsein für diese Liste von Tests in jedem Fall sinnvoll
- Jeder muss individuell entscheiden, welcher Test Sinn macht
Wie gut ist dein Machine-Learning-Modell?
Oliver Zeigermann /
@DJCordhose
http://bit.ly/m3-ml-quality