Big Data Visualisation in the browser using Elasticsearch, Pandas, and D3
Target audience
- Domain Expert: What is possible in visual exploration?
- Technical Expert: What tools can I use to support the Domain Expert?
Inspiration: Interactive big data for logging with Graylog
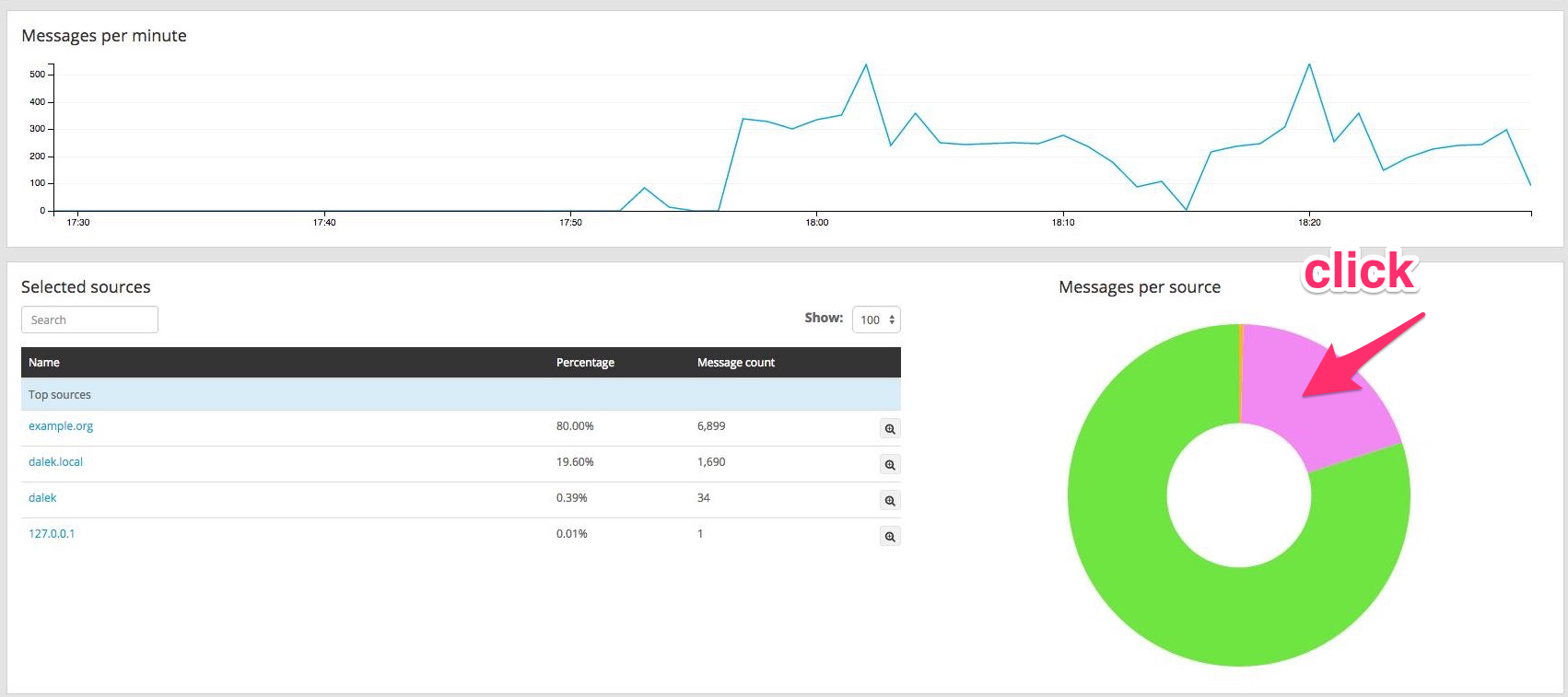
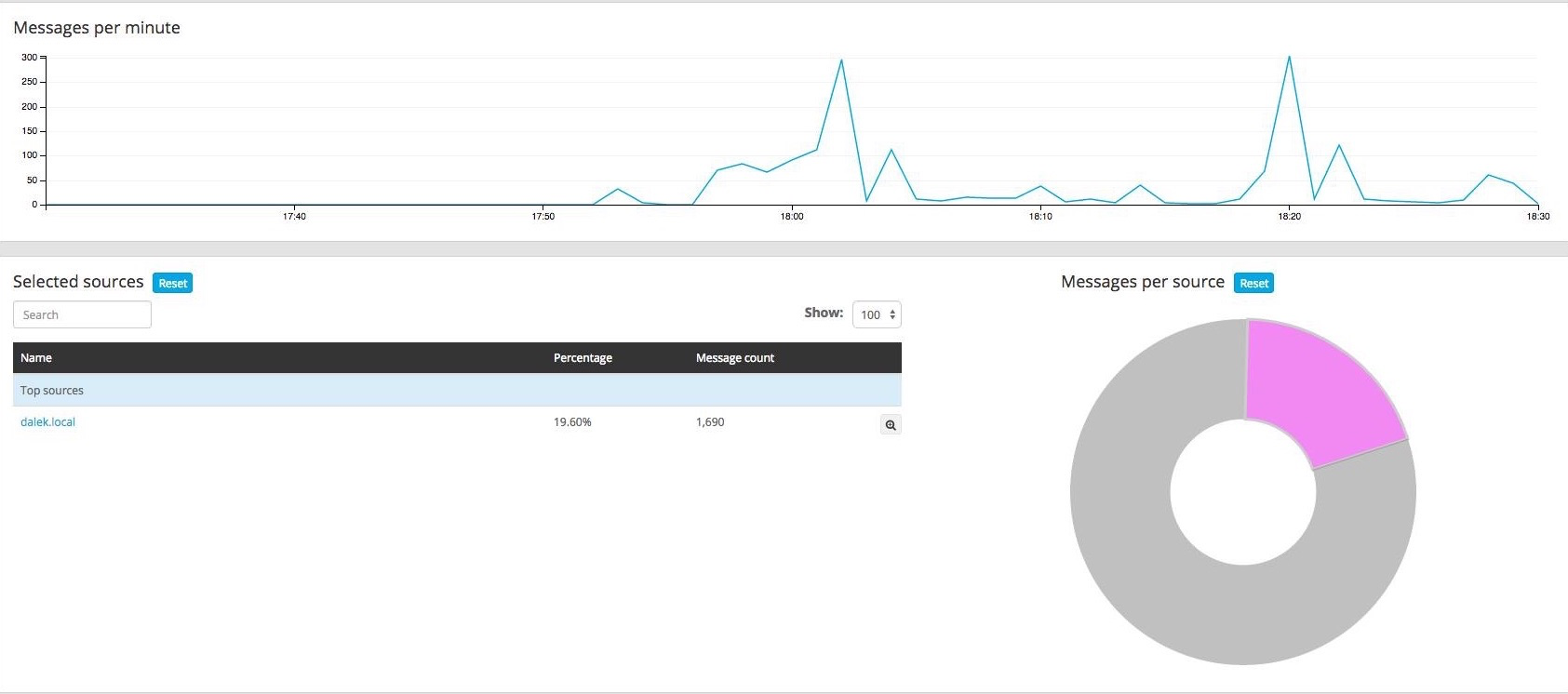
A more complex example using DC.js
no big data, though
A journey through exploring all domestic US flights
for 2001

No specific task or question
Exploring what just might be interesting
Finding the unknown unknowns
Try showing your #data from another perspective with #dataviz

The raw data
approx. 6 million data sets
> wc -l 2001.csv
5967781 2001.csv
approx. 600 MB of data
> ls -hl 2001.csv
573M Jan 10 2016 2001.csv
29 colums, data has gaps, but looks consistent
> head 2001.csv
Year,Month,DayofMonth,DayOfWeek,DepTime,CRSDepTime,ArrTime,CRSArrTime,UniqueCarrier,FlightNum,TailNum,ActualElapsedTime,CRSElapsedTime,AirTime,ArrDelay,DepDelay,Origin,Dest,Distance,TaxiIn,TaxiOut,Cancelled,CancellationCode,Diverted,CarrierDelay,WeatherDelay,NASDelay,SecurityDelay,LateAircraftDelay
2001,1,17,3,1806,1810,1931,1934,US,375,N700��,85,84,60,-3,-4,BWI,CLT,361,5,20,0,NA,0,NA,NA,NA,NA,NA
2001,1,18,4,1805,1810,1938,1934,US,375,N713��,93,84,64,4,-5,BWI,CLT,361,9,20,0,NA,0,NA,NA,NA,NA,NA
2001,1,19,5,1821,1810,1957,1934,US,375,N702��,96,84,80,23,11,BWI,CLT,361,6,10,0,NA,0,NA,NA,NA,NA,NA
2001,1,20,6,1807,1810,1944,1934,US,375,N701��,97,84,66,10,-3,BWI,CLT,361,4,27,0,NA,0,NA,NA,NA,NA,NADoes this at all qualify as big data?
Why not just load it into Excel and fiddle about?
You simple can not
too large
and even if you could: way too slow
even if it was fast enough: does not run in the Browser
even if it does (360 or Google Sheets): is it most interactive?
No known interactive out-of-the-box tool to efficiently work on that
Other Standard tools
- Excel (2011 Mac): truncates
- loads data relatively fast
- truncates after 1M lines
- Google Sheets: nope
- limited to 2.000.000 cells (not lines)
- does not load data at all
- Numbers (Mac): truncates
- loading takes long
- truncates after 64k lines
- Emacs: Low-level operations possible
- loads data very fast with almost no memory overhead
- all operations work smoothly, even editing and saving
Challenge
Handling large amounts of data
while maintaining the interactivity and the intuitive UI
But: data needs to be (physically) close to processing / interaction to make it fast and thus most useful
Like: benefits of Excel and Access at the same time

Sources for data
Hands-on
- What kind of data would you like to explore?
- Do you already have existing data to deal with?
- What kind of data do you already have in an accessible format?
- What tools do you use now to analyze your data? Do they work well?
You can get inspiration from data sources listed on previous slide
After 5-10 minutes report interesting results to full audience
Good oportunity to discuss these questions with your neighbors
The Journey
Making sense of the data step by step
All software shown here is Open Source and Free of Charge
I: Data Wrangling with Pandas
Preparing the data
- Add missing data
- Recombine data
- Add type information / conversion
- Do static pre-analysis to learn about data
- What is the nature of the data (e.g. time series data)?
- Does the data look plausible?
- What visualizations seem most promising?
Kudos to Chi Nhan Nguyen for technical support on this section
Introducing Pandas and friends
All live in the Python world
- http://pandas.pydata.org/: data structures and data analysis tools
- http://www.numpy.org/: fundamental package for scientific computing
- http://matplotlib.org/: 2D plotting library
- https://stanford.edu/~mwaskom/software/seaborn/: statistical data visualization
Step 1: Analysing Samples
Working on a reduced number of random samples
- How is the data quality (e.g. missing or wrong data)?
- Is the data plausible?
- What might be interesting to explore?
Sample Code: Analysis
Reading sample data
s = 10000 # desired sample size
n = 5967780 # complete data size
skip_rows = sorted(numpy.random.choice(np.arange(1, n + 1), (n - s)))
# pandas dataframe (2-dim table structure)
df = pandas.read_csv('../../data/2001/2001.csv', skiprows=skip_rows)
Missing data?
> df.count()
DepTime 9611
CRSDepTime 10000
ArrTime 9590
CRSArrTime 10000
UniqueCarrier 10000
ActualElapsedTime 9590
CRSElapsedTime 10000
AirTime 9590
ArrDelay 9590
DepDelay 9611
Origin 10000
Dest 10000
Distance 10000
Cancelled 10000
CancellationCode 0
Diverted 10000
CarrierDelay 0
WeatherDelay 0
NASDelay 0
SecurityDelay 0
LateAircraftDelay 0Sample Code: Creating Correlation Chart
cols_for_correlation = [
'DayOfWeek', 'DepTime','ArrTime', 'ArrDelay', 'Distance',
'UniqueCarrier_', 'Origin_', 'Dest_'
]
corrmat = df[cols_for_correlation].corr()
seaborn.heatmap(corrmat, annot=True)
Correlations (r)
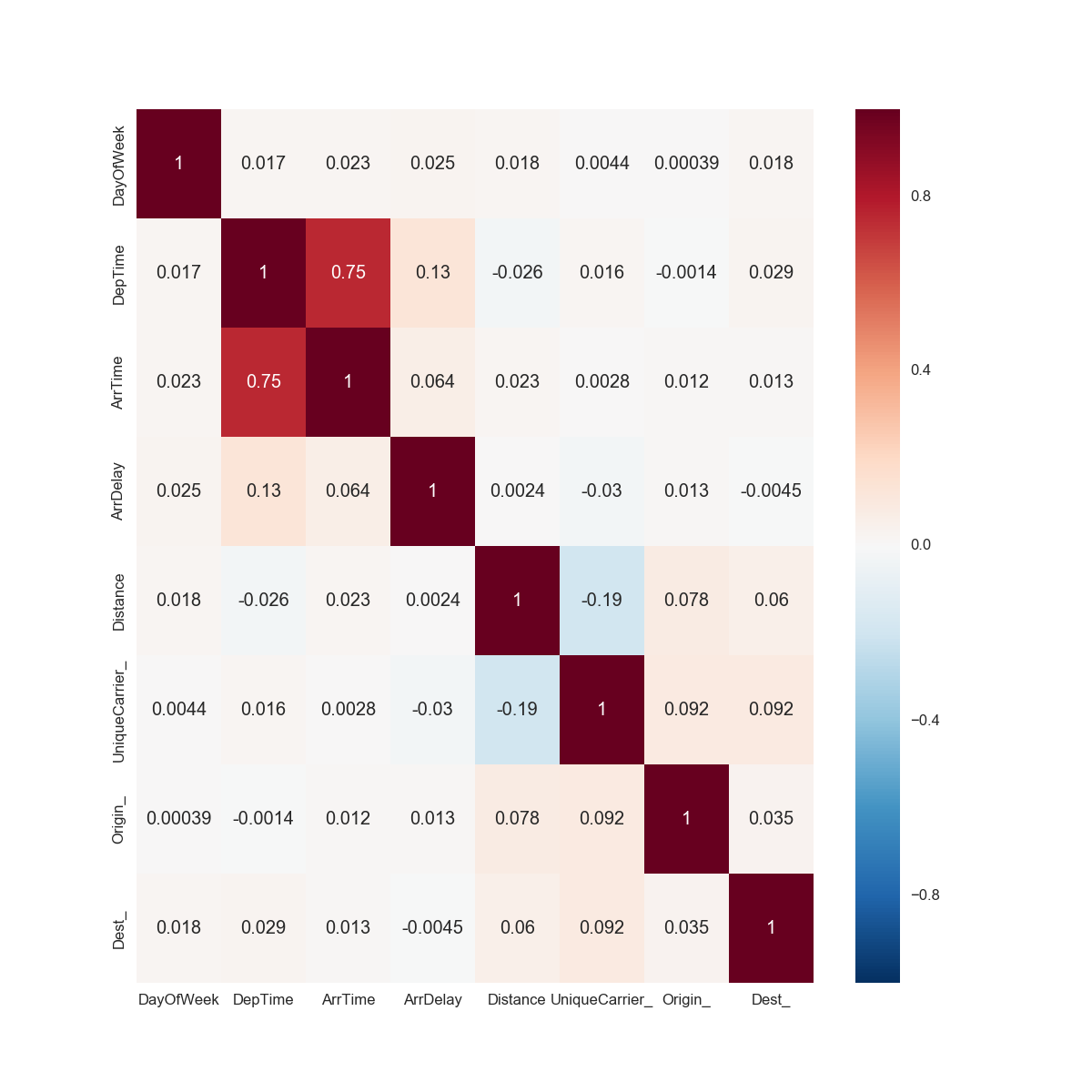
Interesting: Distance / Origin to Unique Carrier
Pearson's r
Pearson's r is a measure of the degree of linear(!) dependence between two variables

By Kiatdd - Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=37108966
This is just linear correlation
correlation coefficient (r) above each figure
Notice: figures at the bottom row obviously are correlated, just not linearly
Need to look at the individual figures
Arrival Time to Departure Time
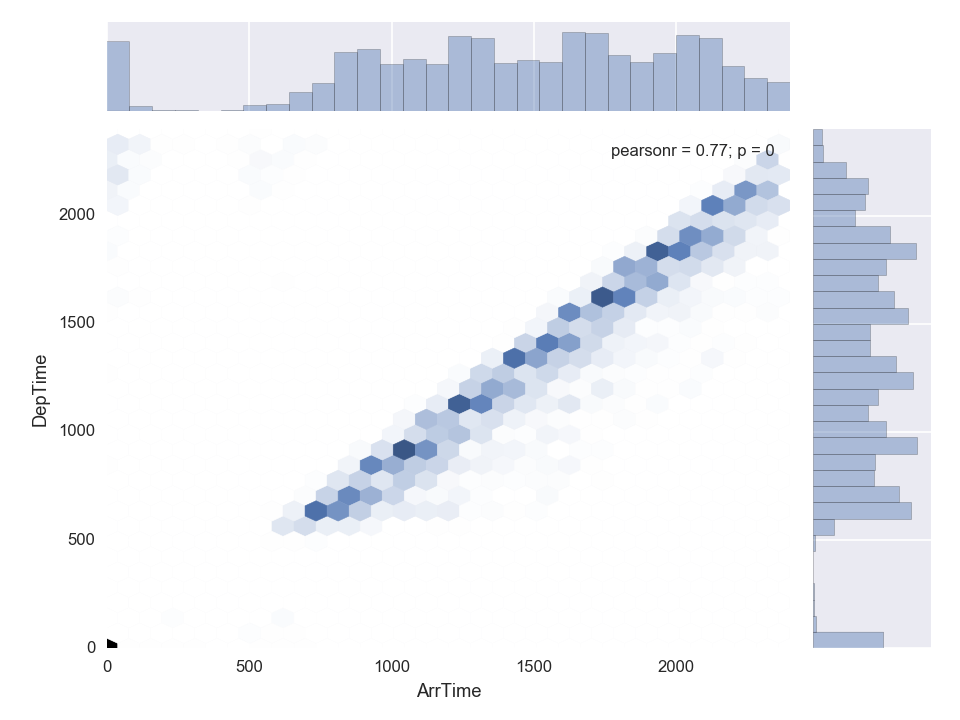
Pearson's r: 0.77, plausible but trivial
Sample Code: 2D Jointplot
seaborn.jointplot(df['ArrTime], df['DepTime'], kind="hex")
Origin to Unique Carrier
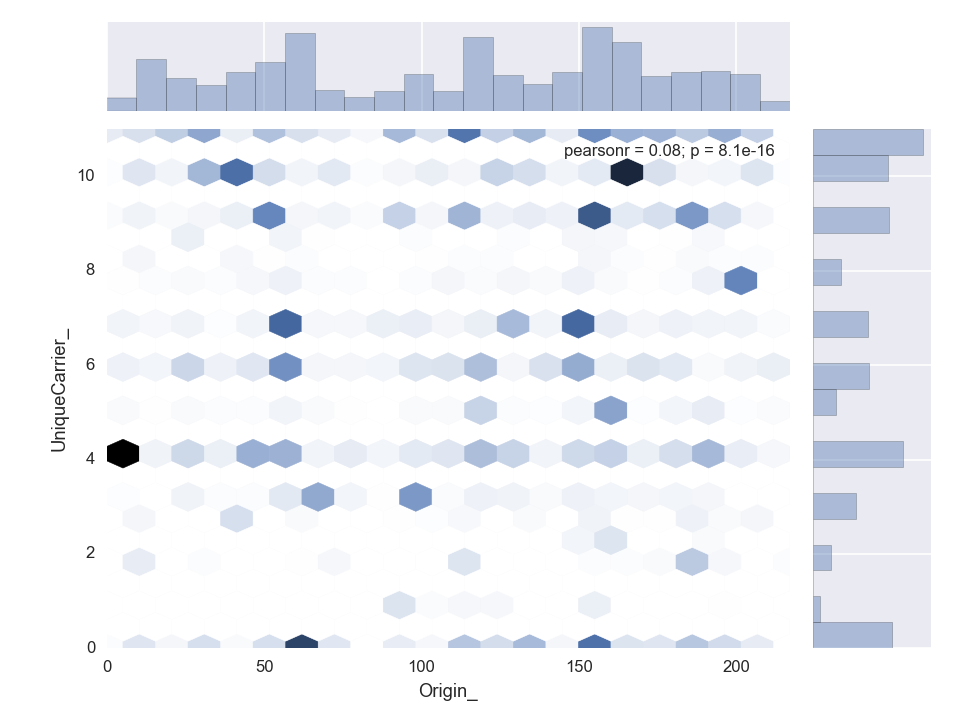
Origin to Unique Carrier
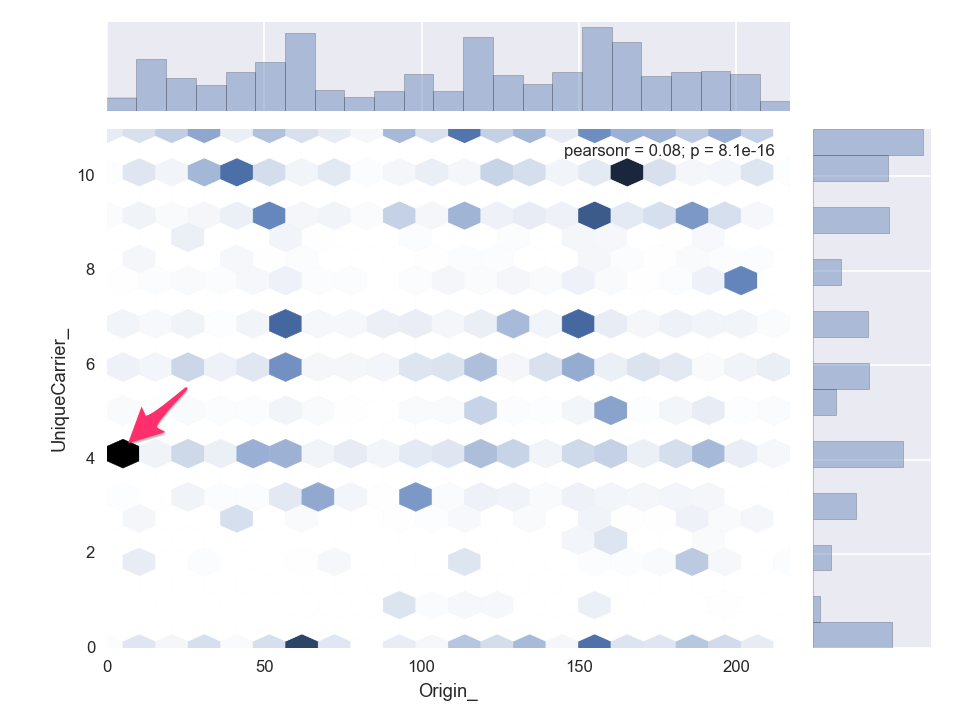
4 = (DL) Delta
Distance to Unique Carrier
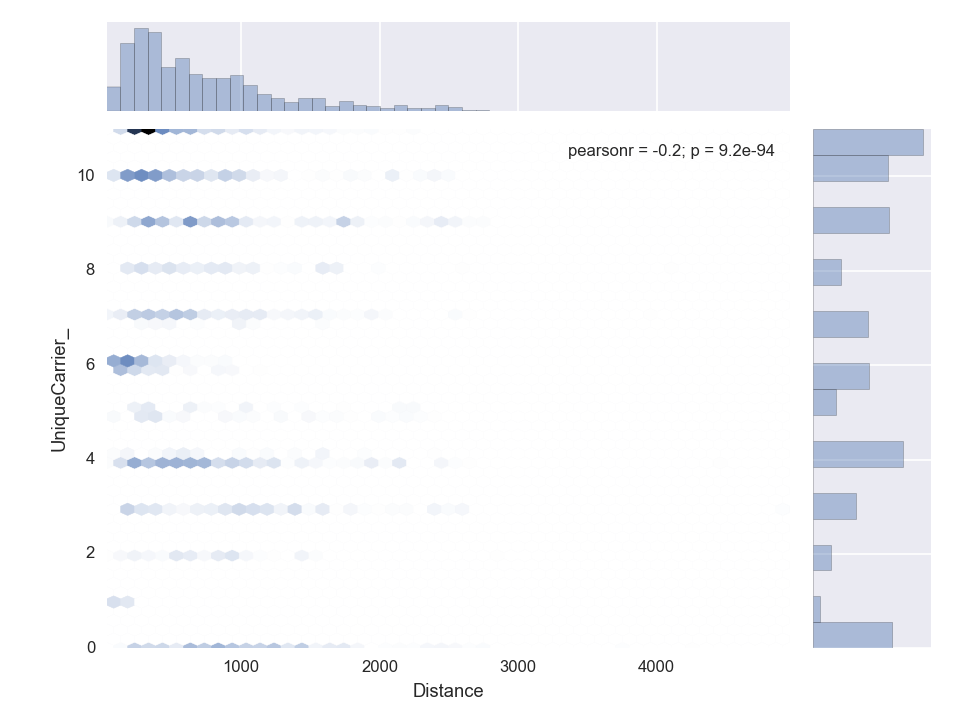
Distance to Unique Carrier
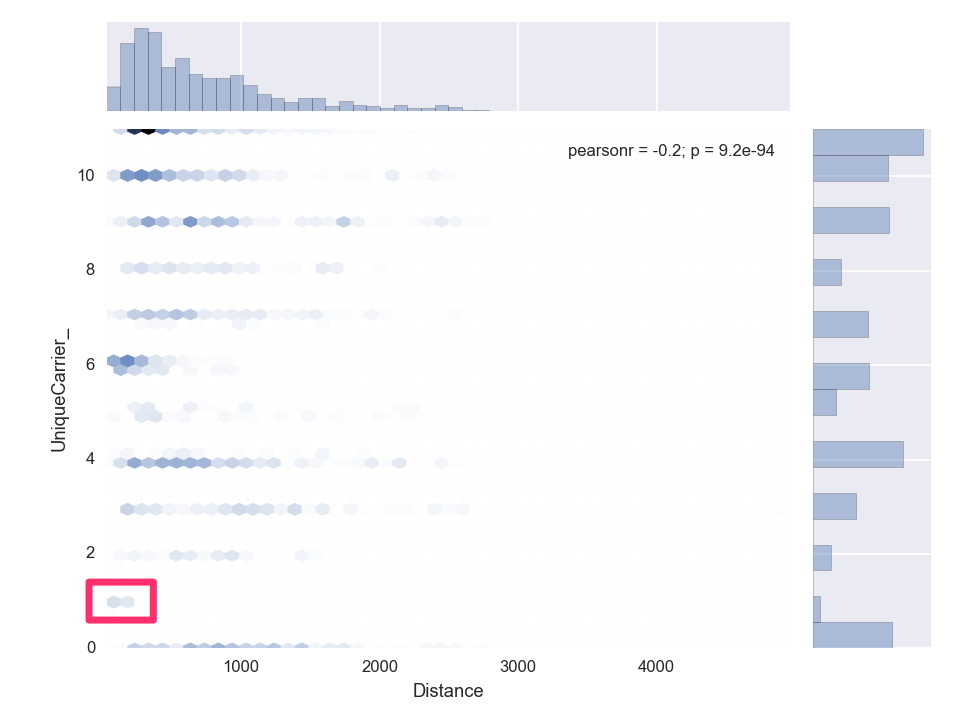
1 = AQ (Aloha Airlines)
How to Start Experimenting?
Get complete code from github: https://github.com/DJCordhose/big-data-visualization/tree/gh-pages/code
Try out analysis part (requires Python with numpy, pandas, matplotlib, seaborn, sklearn to be installed)
python big-data-visualization/code/es/analysis_pandas.pyEasiest to get started with Python: https://docs.continuum.io/anaconda/
Results of Analysis
- A really large set of data
- Data looks plausible
- Many missing values
- Contains obvious correlations
- But also contains non-trivial correlations
- Has timestamps
- Storing and analysing as time series data sounds promising
Bottom line: not an easy, but interesting data set
Big Data in the sense of: too big for Excel, hard to process
Isn't this good enough already?
So far
working on random samples only
time series data not exploited (would be possible with Pandas)
not interactive
Next Step: store data in db to make it flexibly accessible
II: Elasticsearch
Storing and Querying data
Introducing Elasticsearch
https://www.elastic.co/products/elasticsearch
- Search and Analytics Engine
- Indexes and stores structured or unstructured data
- Offers query language to search or aggregate data
Comparing to relational DB
| Relational Database | Databases | Tables | Rows | Columns |
|---|---|---|---|---|
| Indices | Types | Documents | Fields |
Example
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25
}
- index: megacorp
- type: employee
- document: <json body>
- field(s): age
Importing our data into Elasticsearch
using pyelasticsearch
Sample Code: Preparing Elasticsearch
Create an index
from pyelasticsearch import ElasticSearch, bulk_chunks
es = ElasticSearch(ES_HOST)
es.create_index(INDEX_NAME)
Sample Code: Preparing Elasticsearch
Create a mapping to make types clear to Elasticsearch
mapping = {
'flight': {
'properties': {
'SecurityDelay': {
'type': 'integer',
'null_value': -1
},
'Origin': {
'type': 'string'
},
'Cancelled': {
'type': 'boolean'
},
...
es.put_mapping(index=INDEX_NAME, doc_type=DOC_TYPE,mapping=mapping )
Good for performance, query hints, and index size
Sample Code: Reading and Cleaning
# reads all data into data frame in memory
df = pd.read_csv('../../data/2001/2001.csv')
# missing value will be filled with -1
df.fillna(-1)
# add a timestamp to each row
df['@timestamp'] = df.apply(lambda row:
pd.Timestamp('%s-%s-%s;%04d'
%(row['Year'], row['Month'],
row['DayofMonth'], row['CRSDepTime'])))
# custom convert cancelled into boolean
df['Cancelled'] = df.apply(lambda row:
False if row['Cancelled'] == 0 else True)
Let all this boil for a few hours ...
... and make sure you have around 25GB of RAM to process it ;)
Checking time series data for the first time
using Kibana adhoc queries
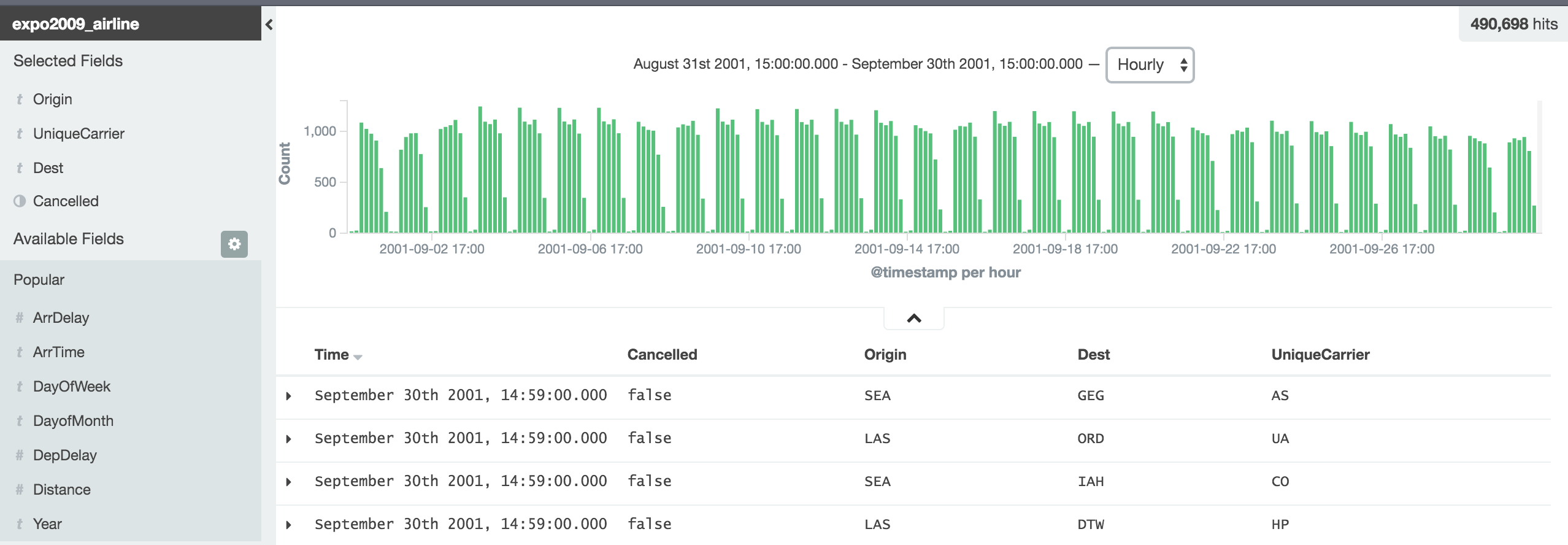
Demo: filter for 'Cancelled:false'
Interactive Dashboards also possible
Kibana
- generic frontend for Elasticsearch
- browser based
- allows for dashboards
- also allows to make arbitrary adhoc queries
III: Interactive Exploration in the Browser
But why in the Browser
1: Zero-Installation for the user
2: Available on almost every device
3: Interactivity comes naturally
Interactive Dashboard
Already possible with Kibana
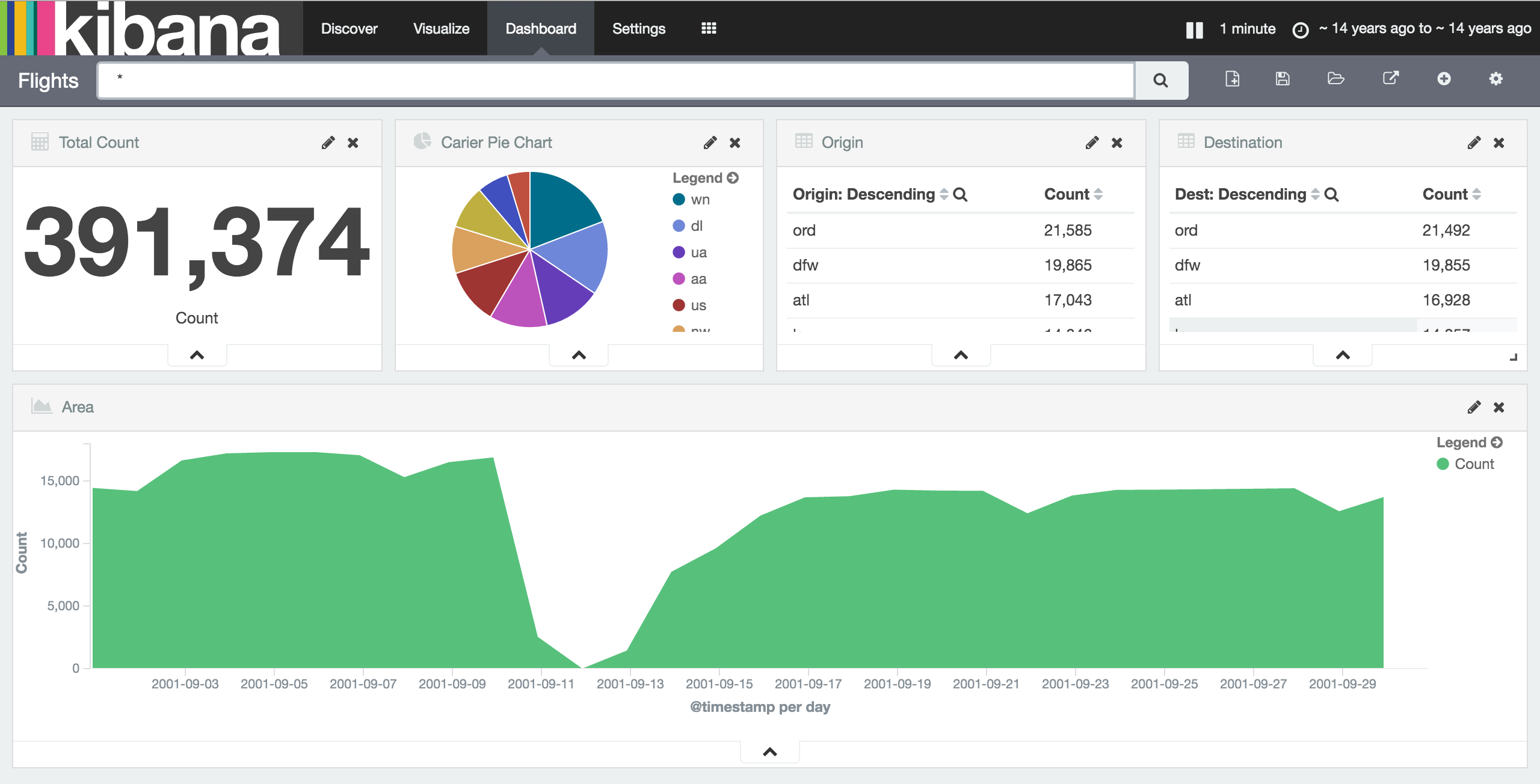
Demo: Clicks trigger requests, responses update graphics
What is still missing?
Low-latency interaction (Latency more obvious when Elasticsearch and Browser are not co-located on the same machine)
(Limited) offline access
Charts limited to what Kibana offers
D3.js: Dynamic graphics in the browser
Data based vector graphics (SVG)
D3.js
- Predominant Open Source visualization framework
- Hard to master, as quite low level
- Good idea to put an abstraction on top of it
Crossfilter: Filtering millions of data sets in real time
- http://square.github.io/crossfilter/
- Can filter up to millions of data sets in real time in the browser
- Loads data in memory
- Data sets are indexed when loaded (also in memory)
- You specify what you want to filter using dimensions
dc.js: Charting with D3 and Crossfilter
- http://dc-js.github.io/dc.js/
- Prebuilt integration of D3 and Crossfilter
- offers a couple of diagram types that are useful for exploring data
- bar
- pie
- many more
dc.js Demo
This is very impressive
but is it also useful?
Be careful not to overdo things
Try not to display too many dimensions in order not to overwhelm the user
3-4 should be a save choice, 5-6 might be possible if not too different in nature
The brain is great at recognizing patterns
Don't make it too hard for it, though
Choose the graphical encodings...
... that are best visually decoded.
Graphical Encodings
http://strataconf.com/big-data-conference-ny-2015/public/schedule/detail/43411
Initial Design of our Dashboard
Part #1: Order
Ordering Values: Possisbly first pie chart ever
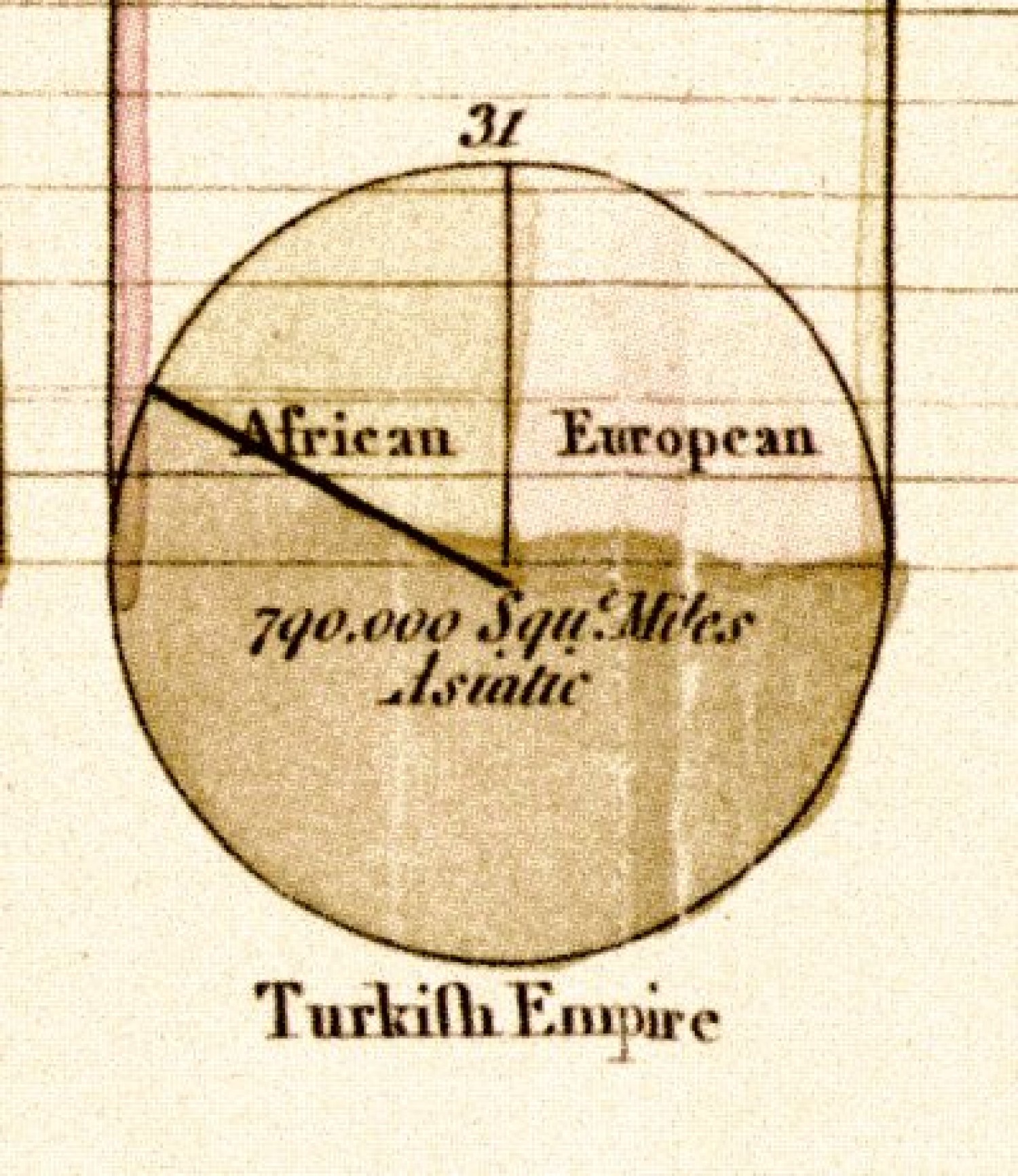
http://blog.visual.ly/12-great-visualizations-that-made-history/
Display Carriers as a Pie Chart
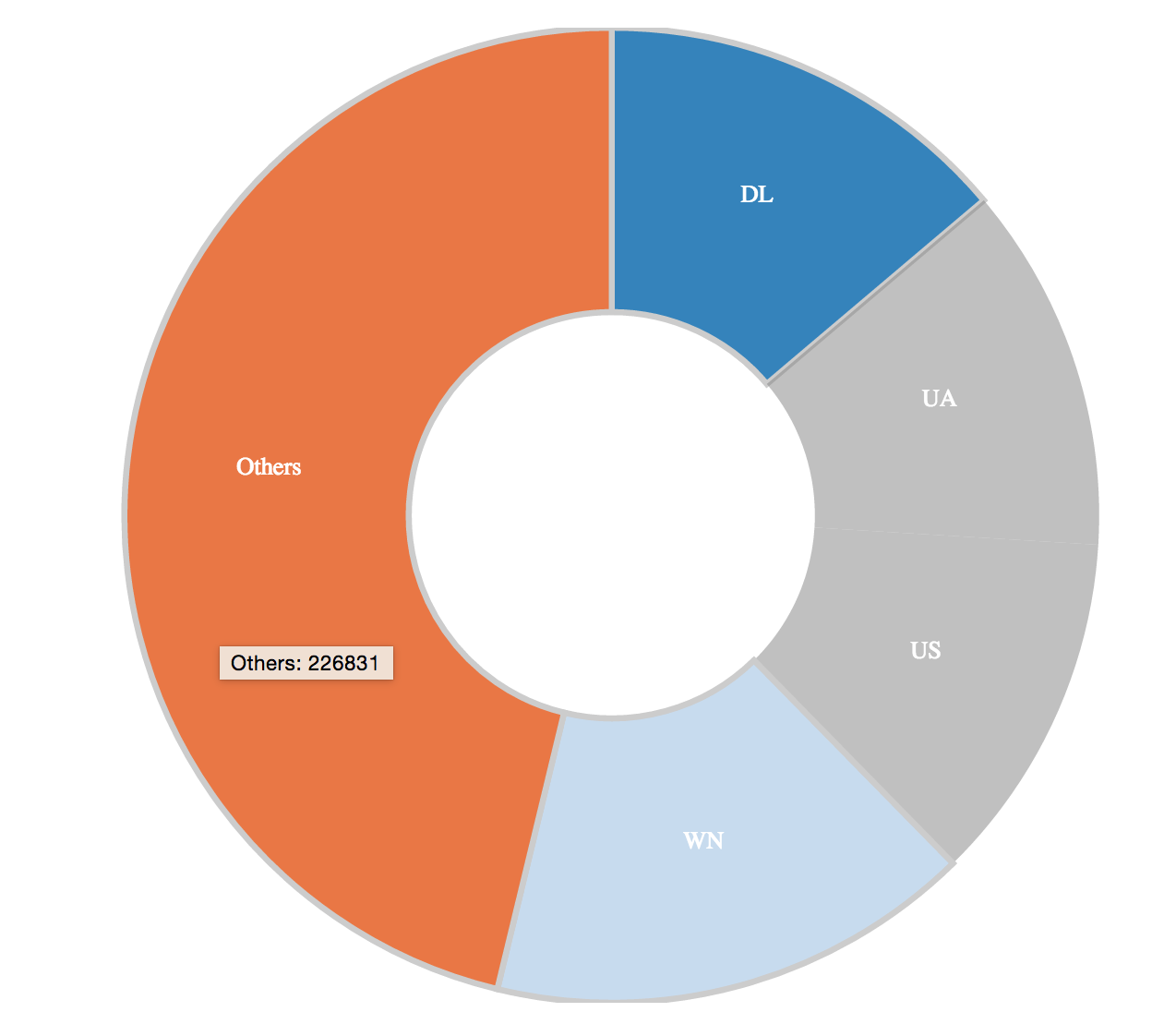
Code Sample: creating the pie chart
var pieChartCarriers = dc.pieChart("#pie");
pieChartCarriers
.slicesCap(5)
.dimension(carrier)
.group(carrier.group().reduceCount());
Part #2: Connections
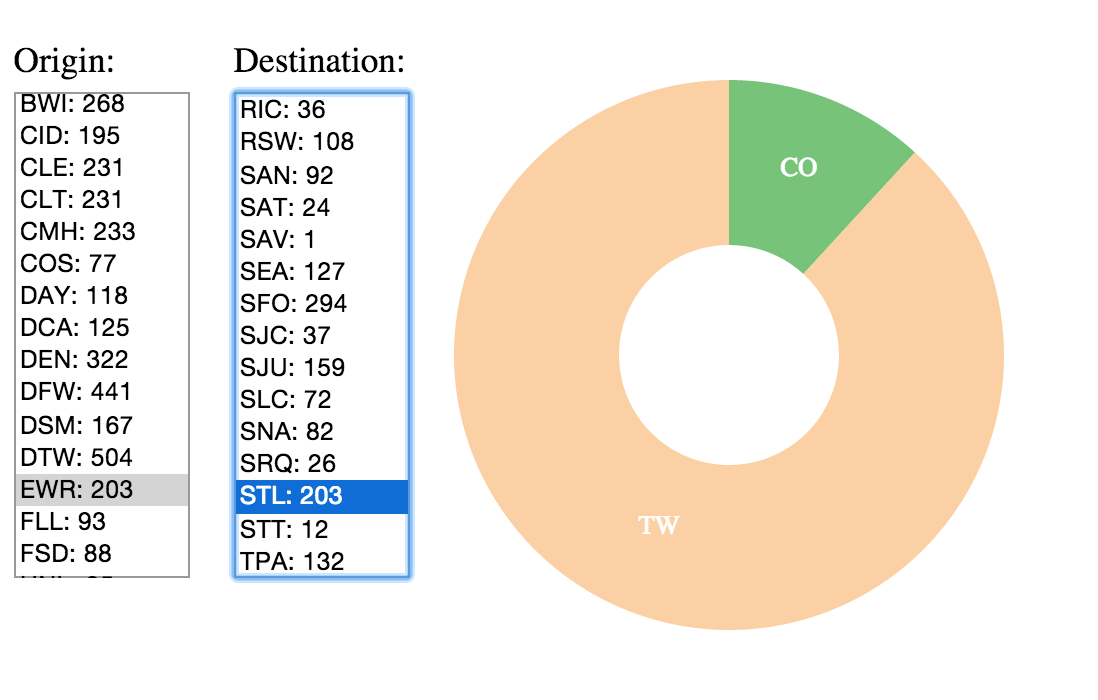
Origin, Destination, Carriers combined
Part #3: Time
Time Series: London Underground ad from 1928

Filtering using Brushes
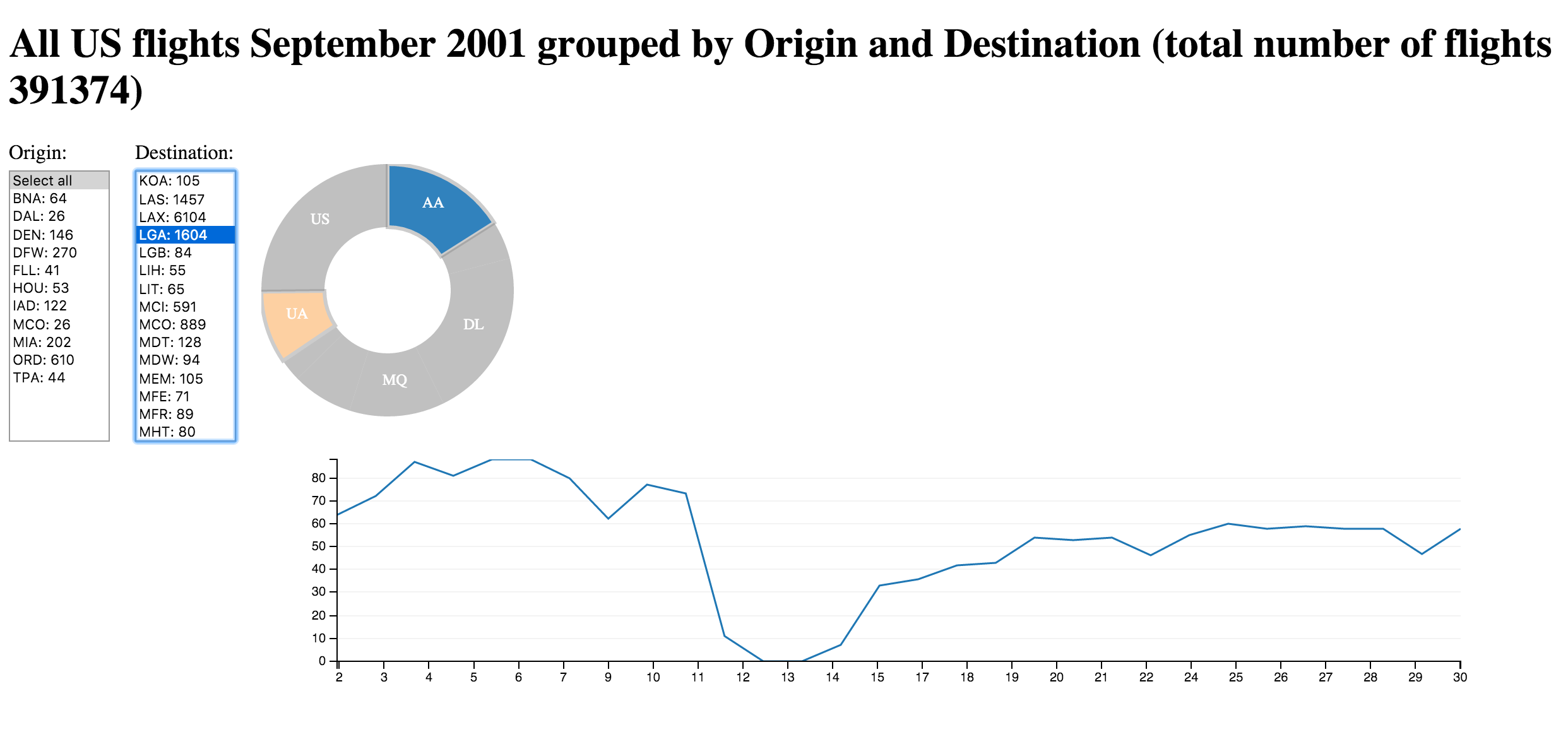
Code for creating the line chart
var chart = dc.lineChart("#series");
chart
.dimension(date)
.group(date.group())
.brushOn(true));
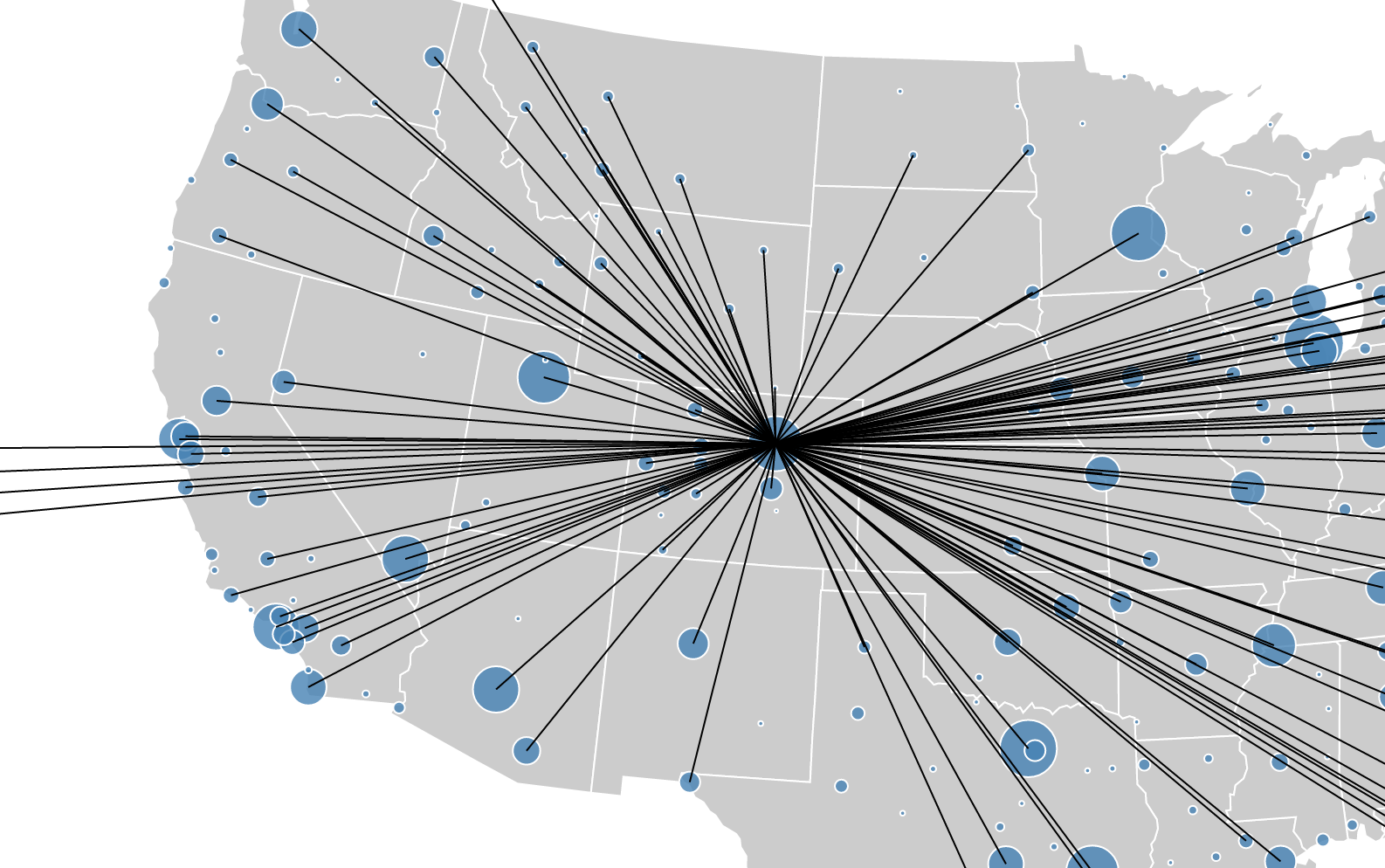
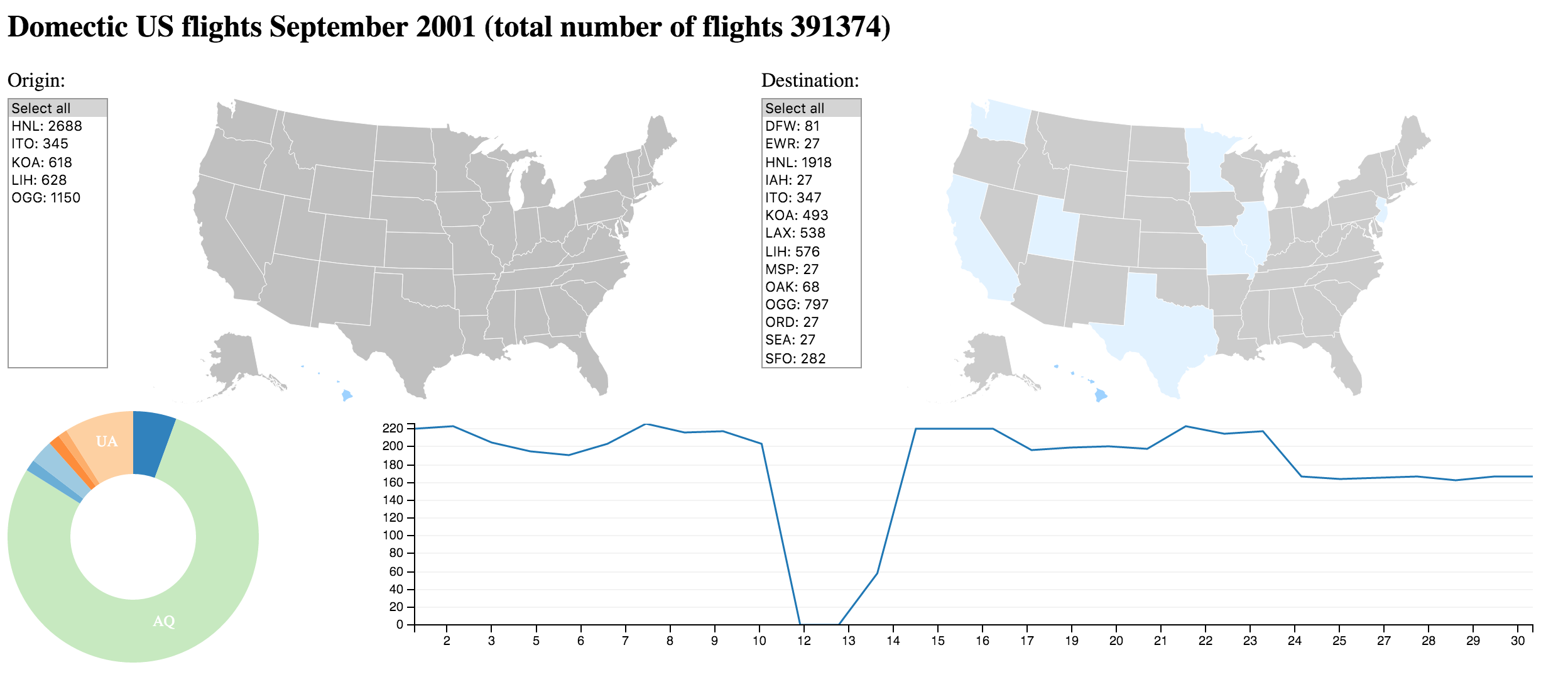
Part #4: Map
Map
Hands-on
Experiment with our Dashboard
http://bit.ly/dataviz-map-demo
It should even work on your smartphone
Is there anything of interest you found out?
Give it 5 minutes max.
If you need a clear assignment:
What are the origins of Delta flights to STL (St Louis)? Why?
Previous examples worked on data dumps, not on dynamic queries to Elasticsearch
User can choose partition with dynamic Query to Elasticsearch
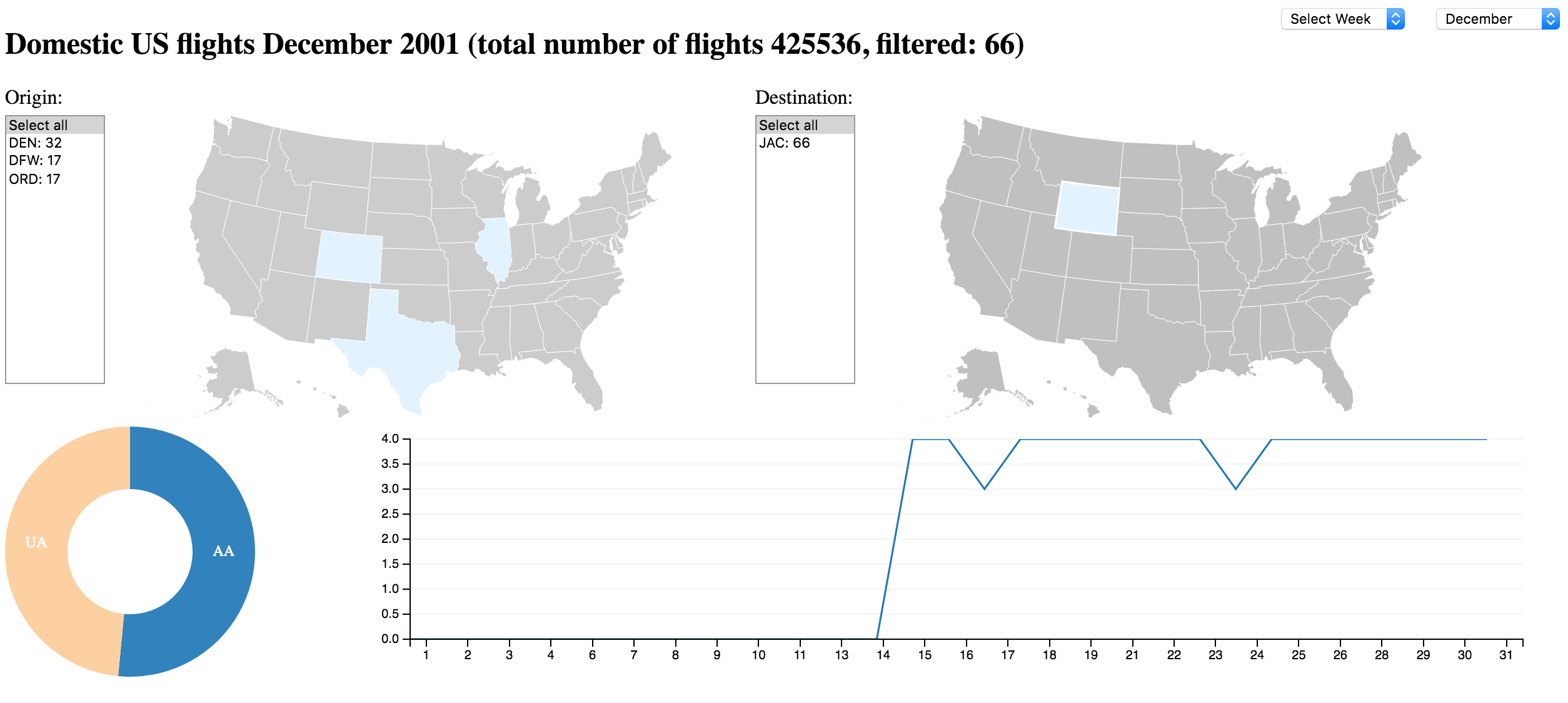
Will not work on your local machine (needs Elasticsearch running)
D3 loading Segments from Elasticsearch
- Elasticsearch delivers data over HTTP/JSON using query
- D3/Crossfiler/DC displays partition of data
- Partition could be month
- Manually selected by user
IV: Data Exploration Examples
Coming back to questions from low level analysis in first part
Why only short flight distances for Carrier Aloha Airlines (AQ)?
Answer
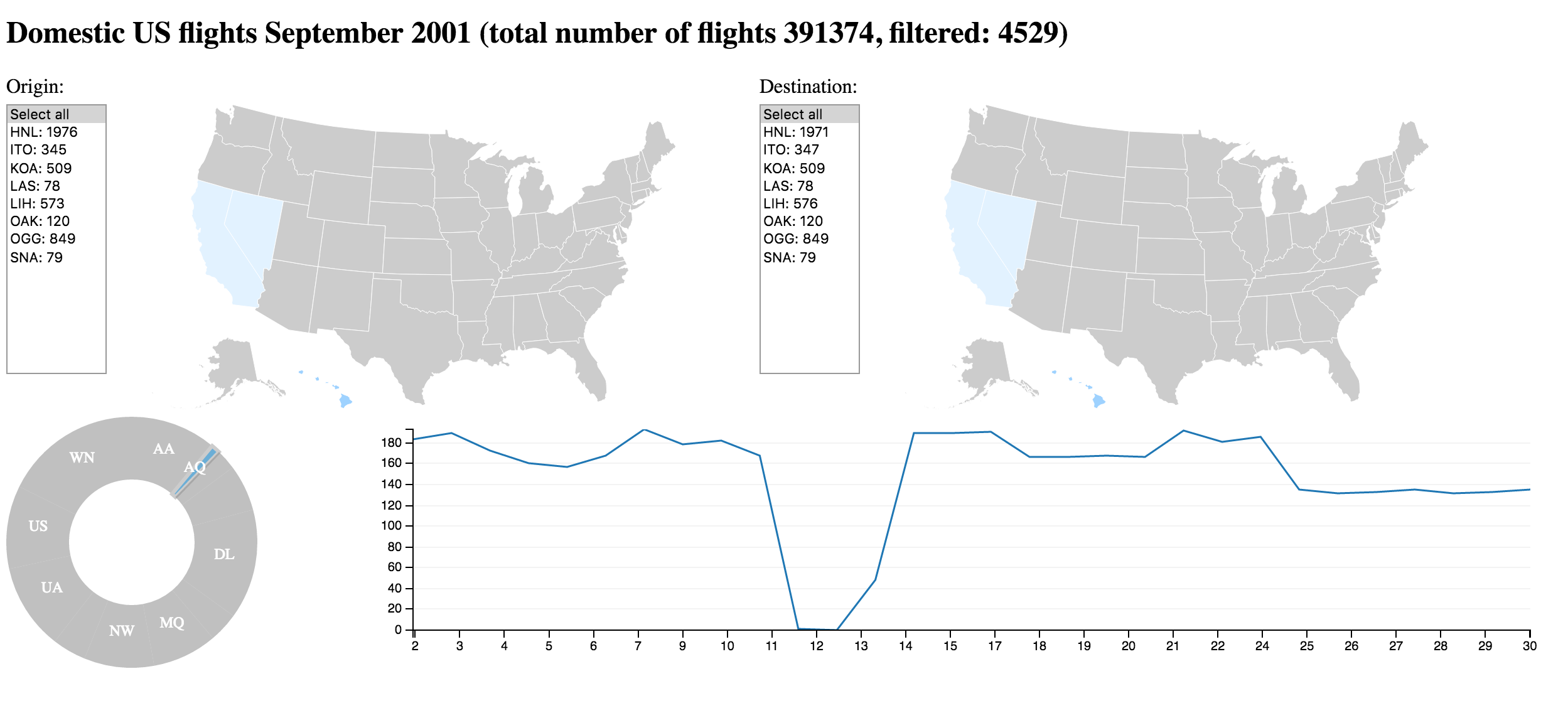
Aloha Airlines (AQ) mainly flies between Hawaii and West Coast (California/Nevada)
What is the prominent Origin for Carrier Delta (DL)?
Answer
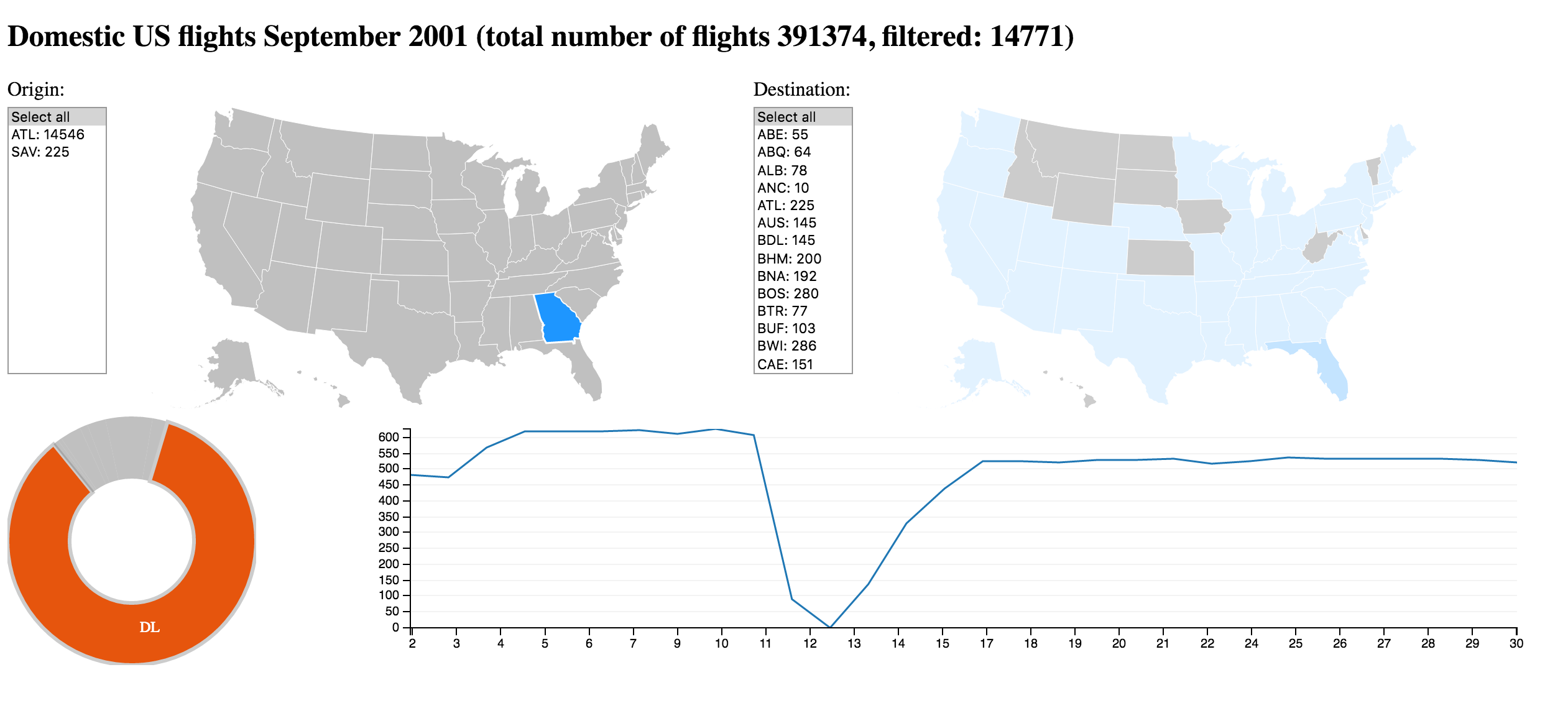
Delta (DL) mainly flies from Atlanta (ATL) its headquarter and largest hub
Resources
- TheGamma: Simple code behind interactive articles
- Kyran Dale: Data-visualization with Python and Javascript; Crafting a data-viz toolchain for the web
- Great D3 visualizations
- Data Visualization for Human Perception
- When Data Viz Trumps Statistics
- Discovering and understanding patterns in highly dimensional data
- Worlds, not Stories: data visualization as a macroscope
- Interactive in-browser 3D visualization of datasets
Wrapup
- Python based tools are most advanced to prepare data and give an analytical overview
- Pyelasticsearch allows to push that data into Elasticsearch
- Elasticsearch allows for very flexible and fast queries on large amounts of data
- The Browser is the ideal platform to explore data (no installation, available everywhere)
- D3, crossfilter, and DC help you to interactively explore your data visually
- Elasticsearch can deliver data in chunks the Browser can digest
Thank you!
Slides: http://bit.ly/data-exploration-odsc
Complete Code: https://github.com/DJCordhose/big-data-visualization/tree/gh-pages/code
Ping me for questions / help / comments: http://zeigermann.eu / @DJCordhose